

ITインフラ作業を楽にしてくれるAnsibleですが、処理を定義するplaybookは、YAMLの書式で記述しないとなりません。一見、YAMLは簡単に見えるのですが、書式が正しくないとplaybook実行時のエラーの原因となります。YAMLの規約を正しく理解することが、Ansibleを使う最初のハードルになります。ううう、めんどくさい。
1. YAMLのデータ形式
YAMLのデータ形式には、構造を持つコレクション と 構造を持たない スカラ があります。そしてコレクションの種類には シーケンス と マッピング があります。
プログラマやSEの方々には、以下の関係で覚えるのが分かりやすいです。
| シーケンス | 配列, リスト |
| マッピング | 連想配列, ハッシュ |
| スカラ | 単一のデータ, スカラ値 |
① シーケンス
順序を表すデータ構造です。例を示します。
- HumanResources - Sales - Engineering
・「-」(ハイフン)を先頭にして記述します。
・「-」の後には空白を1個以上入れます。
・各行の間に空行が入っていても継続されます。
データ構造を図で理解するとこんな感じです。

② マッピング
キーと値の対応でデータを表現する構造です。
director: Yamada office: Tokyo area_code: 100
・キーの後に「:」(コロン)を付けて、その右に値を記述します。
・「:」の後には空白を1個以上入れます。
・各行の間に空行が入っていても継続されます。
データ構造を図で理解するとこんな感じです。

③ スカラ
シーケンスやマッピングに格納する値として使用されることが多いです。
・文字列は、「”」(ダブルクォート) または 「’」(シングルクォート) で囲んで記述します。
・数値(整数,少数)はそのままの形式で記述します。
・真偽値には、true と false があります。
・空を意味する値として null があります。
さて、「”」 または 「’」で囲んでいない文字列はどのように扱われるでしょうか?
答えは、暗黙的な型判定によってAnsibleが判定します。従って、確実に文字列として表現したい場合は、「”」 または 「’」で囲んでおくことをお勧めします。
ここまでは、頭が追いついてこれますよね。。
2. ブロックスタイルとフロースタイル
さあ、意地悪なYAMLの始まりです。
1. で紹介したシーケンスとマッピングの記述例は ブロックスタイル と呼ばれ、1行に1要素を定義するスタイルです。
一方で、1行で全ての要素を定義するスタイルとして フロースタイル があります。それぞれ以下のように記述します。
・シーケンスの記述方法は、[ ] で囲んだ中に、要素を「,」(カンマ)区切りで定義します。
・マッピングの記述方法は、{ } で囲んだ中に、要素を「,」(カンマ)区切りで定義します。
1.①のシーケンスデータをフロースタイルで表記すると以下のようになります。
[HumanResources, Sales, Engineering]
1.②のマッピングデータをフロースタイルで表記すると以下のようになります。
{director: Yamada, office: Tokyo, area_code: 100}
フロースタイルで、マッピングを記述するときも、「キー:」の後ろには1個以上の空白を入れて下さい。
要素を区切る「,」の前後の空白は入れても入れなくてもOKです。
ブロックスタイルよりもフロースタイルのほうがプログラマには理解しやすそうですが、Ansibleではブロックスタイルで記述するケースのほうが多いです。
3. インデントと階層構造
YAMLが嫌いになる最初のハードルは、インデントによる階層構造の表現です。
ブロックスタイルにおいて、改行の後にインデント(空白1文字以上)を行うことによって、階層構造を表現します。pythonに慣れている人は、インデントがデータやプログラムの構造を表現していることに違和感はないと思いますが、C言語をはじめとするブレースによるブロック構造の表現に慣れている人にとっては、許せん…って感じです。でも、これに慣れないとAnsibleを使っていけません。
① シーケンスの入れ子構造
1.①のシーケンスデータは、一般的な会社の中の部門を一覧にした例でした。
例えば、Engineeringという大部門はなくて、実際にはHardware, Software, Network という3つの小部門で構成されていたとしたら、どのような構造になるでしょうか。インデントで入れ子構造を表現してみます。
- HumanResources - Sales - - Hardware - Software - Network
・4行目のように、値を持たない「-」だけの要素を記述して、その下の行から入れ子となるシーケンスをインデントして記述します。
・同じ深さのシーケンス要素は、インデントの位置を合わせなければなりません。
データ構造を図で理解するとこんな感じ。配列の中に配列が入れ子になっています。

一見すると、以下のように記述する方が正しいように思えますが、Hardware, Software, Network は、大部門の入れ子にはなりません。
- HumanResources - Sales - Hardware - Software - Network
yqコマンドを使って、YAMLをjson形式に変換すると構造がよく理解できます。
以下は最初のYAMLデータ(test1.yml)をjson形式に変換した出力です。
$ yq -o=json test1.yml
[
"HumanResources",
"Sales",
[
"Hardware",
"Software",
"Network"
]
]
以下は2番目のYAMLデータ(test1no.yml)をjson形式に変換した出力です。あらら、Hardware, Software, Network は大部門 Salesの継続行として扱われていますね。
$ yq -o=json test1no.yml [ "HumanResources", "Sales - Hardware - Software - Network" ]
② マッピングの入れ子構造
1.②のマッピングデータは、ある部門の属性を表した例でした。
更に、director である Yamada さんの属性を入れ子にして格納してみたいと思います。このような例になります。
director: name: Yamada phone: "100-10001" mail: "yamada@xxx.yyy.com" office: Tokyo area_code: 100
・1行目のように、値を持たないキーだけの要素(上記の例では director:)を記述して、その下の行から入れ子となるマッピングをインデントして記述します。
・同じ深さのマッピング要素は、インデントの位置を合わせなければなりません。
データ構造を図で理解するとこんな感じ。ハッシュの中にハッシュが入れ子になっています。

この例も、yqコマンドを使って、YAMLをjson形式に変換すると構造がよく理解できます。
$ yq -o=json test2.yml
{
"director": {
"name": "Yamada",
"phone": "100-10001",
"mail": "yamada@xxx.yyy.com"
},
"office": "Tokyo",
"area_code": 100
}
③ シーケンスの中にマッピングを入れ子する
1.①のシーケンスデータの最初の要素に、マッピングのデータを格納してみましょう。シーケンスの最初の要素を入れ子にして、1.②のマッピングデータを格納します。部門の名前が分からなくなってしまうので、キー departmentを追加しています。
-
department: HumanResources
director: Yamada
office: Tokyo
area_code: 100
- Sales
- Engineering
・1行目は、3.①のルールに従い、値を持たない「-」だけの要素を記述して、その下の行から入れ子となるマッピングをインデントして記述しています。
でも、この書式、Ansibleのplaybookであまり見ません。よく見るのは以下の書式です。
- department: HumanResources director: Yamada office: Tokyo area_code: 100 - Sales - Engineering
実は、この2つのデータは等価です。
後者のデータの1行目「- department: HumanResources」で1番目の要素はマッピングであることが分かり、その後の行のインデントが揃っているので同じマッピングの要素として扱われる、のだそうです(笑)。
もう慣れるしかない、ってことですね。
データ構造を図で理解するとこんな感じ。配列の中にハッシュが入れ子になっています。
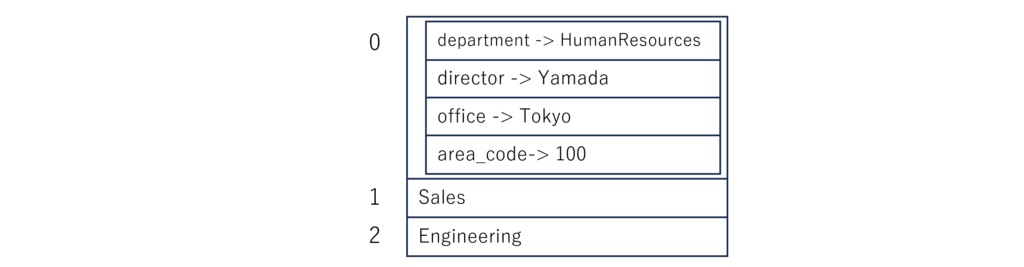
この2つのYAMLデータも、yqコマンドを使って、YAMLをjson形式に変換すると同じjsonデータになります。
[
{
"department": "HumanResources",
"director": "Yamada",
"office": "Tokyo",
"area_code": 100
},
"Sales",
"Engineering"
]
④ マッピングの中にシーケンスを入れ子する
1.②のマッピングデータのキー officeの値にシーケンスのデータを格納してみましょう。
director: Yamada office: - Tokyo - Ohsaka - Kyoro area_code: 100
・2行目のように、値を持たないキーだけの要素(上記の例では office:)を記述して、その下の行から入れ子となるシーケンスをインデントして記述します。
データ構造を図で理解するとこんな感じ。ハッシュの中に配列が入れ子になっています。
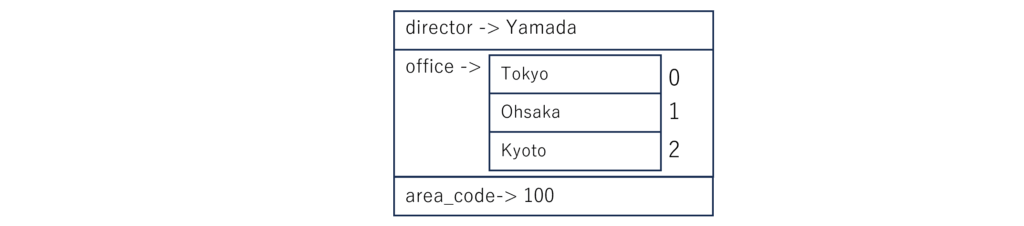
yqコマンドを使って、YAMLをjson形式に変換すると構造は以下のようになっています。
{
"director": "Yamada",
"office": [
"Tokyo",
"Ohsaka",
"Kyoro"
],
"area_code": 100
}
4. Ansibleの古い書式が更に僕らを混乱させる
更に、Ansibleが嫌いになる情報があります(笑)。
Ansibleでは、「キー=値」というパラメタの指定方法もあります。これはAnsibleの登場当初、分かりやすくコマンドを実行するために、既存のシェル文化に寄せるという思想によるものらしいです。
例をあげます。
以下はターゲットノードにファイルをコピーするplaybookです。どちらも同じ結果になります。
--- - hosts: all tasks: - copy: src=test.sh dest=/tmp/test.sh
---
- hosts: all
tasks:
- copy:
src: test.sh
dest: /tmp/test.sh
前者の書き方は、フロースタイルではありません。従来との互換仕様です。
推奨される書き方は、後者のブロックスタイルの記述方法です。
5. インデントは空白何個?
インデントは空白1個以上あればOKです。但し、同じシーケンスの要素、同じマッピングの要素のインデントは揃えなければなりません。
一般的には、空白2個とするのが多いようです。公式ドキュメントのサンプルコードも2個です。
6. その他もろもろ
・先頭の「—」は、「ここから新しいドキュメントが始まる」という意味を持つドキュメント開始マーカーです。Ansibleのplaybookでは書かなくてもOKなのですが、YAMLの規約に従えば、書いておくのが正しいです。
・#の右側はコメント文としてみなされます。
---
# Copy process
- hosts: all
tasks:
- copy:
src: test.sh # file to be copied
dest: /tmp/test.sh # destination path
広告主へのリンク
Ansibleのテストは、ミニPCにLinuxをインストールしてKVMで仮想マシンを作成して行っています(私はこの3台を使っています)。ミニPCは、Linuxのお勉強にとても良いよー。

コメント